어디선가 누군가에게 위성영상을 이용한 어떠한 처리나 확인을 요청받아 이를 진행해야 하는 경우, 저는 주로 Landsat을 다운로드하는 것부터 작업을 시작합니다.
무료로 얻을 수 있다는 것이 가장 큰 이유이고, Landsat-8에 이르기까지의 누적 데이터가 1972년부터 현재까지를 커버하기 때문에 웬만해서는 원하는 날짜와 장소에 대한 데이터를 얻을 수 있다는 것도 다른 이유입니다.
30미터 급의 해상도 문제가 마음에 걸릴 수 있으나, 정밀한 모니터링이 목적이 아닌 이상 크게 문제되지는 않으며, 최근에는 Sentinel-2 데이터를 이용해 이를 보완할 수도 있습니다(밴드에 따라 10, 20, 30 미터 해상도).
최종 결과물이 무엇이냐에 따라 달라지겠지만, 보다 ‘정확한’ 결과물을 얻기 위해서는 일반적인 전처리 과정(대기, 방사, 지형 보정 등)을 거쳐야 하고, 영상의 단순 DN(Digital Number)에서 radiance로 변환하는 과정도 필요합니다. Landsat-7을 예로 든다면 이 링크의 11.3.1과 같은 과정을 의미합니다. 이러한 과정을 거쳐야 ‘유의미한’ 값인 reflectance(11.3.2)나 온도(11.3.3), 각종 인덱스 등을 산출해낼 수 있습니다. 그리고 이 과정을 위해서는 메타 데이터 내에서 각 밴드에 대한 특정 파라미터를 확인해야 하고 이를 ENVI의 Band Math 에서 적용해야 합니다.
그런데 여기까지 쓰고 나니, ‘이 데이터를 왜 써야 하는거야…?’ 라는 의문이 드네요.
그렇기 때문에 현재 Landsat를 제공하고 있는 USGS에서는 Landsat의 Level 1 데이터 뿐만 아니라 Level 2인 ‘Surface Reflectance’ 데이터도 제공하고 있습니다.
저의 경우 Landsat 데이터를 검색할 때 http://earthexplorer.usgs.gov/ 를 주로 이용하는데요, Data Sets의 Landsat Archive하부를 보면 다음과 같이 구분이 되어 있습니다.
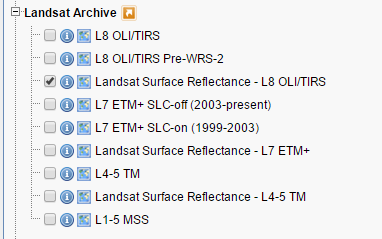
어떠한 차이를 가지고 있는지를 확인하기 위해 동일지역에 대한 ‘L8 OLI/TIRS’ 데이터와 ‘Landsat Surface Reflectance – L8 OLI/TIRS’ 데이터를 다운로드 하였습니다. 각각이 가지는 밴드 정보는 다음과 같습니다.
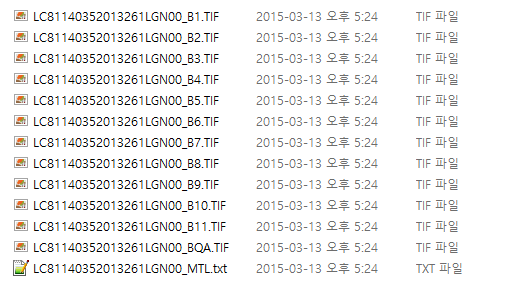
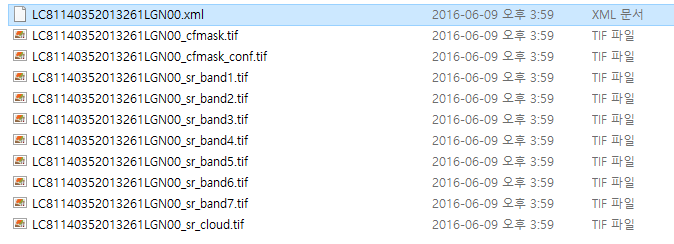
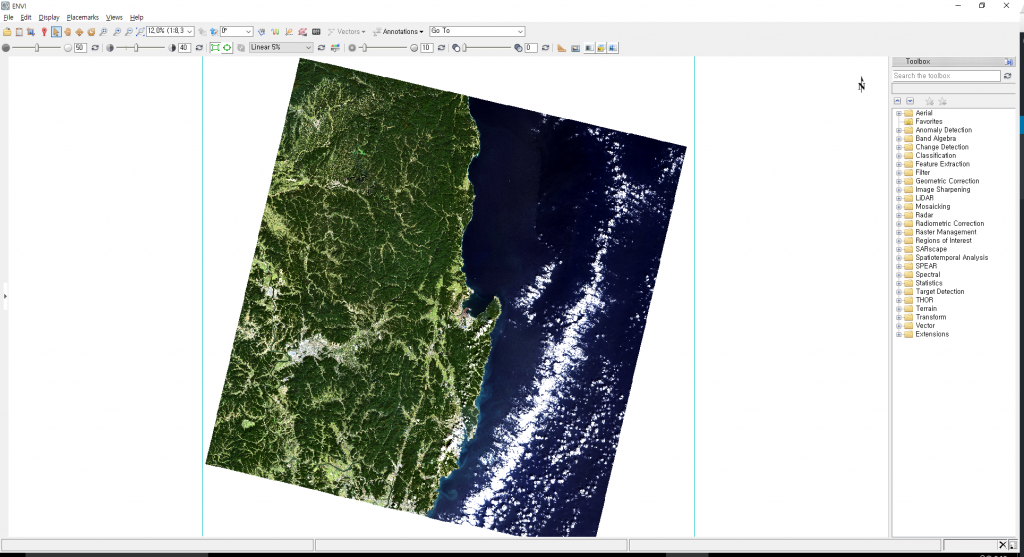
상단이 L1에 대한 데이터 목록, 하단이 L2에 대한 데이터 목록입니다. 우선 밴드 개수가 틀리고, 이름도 다름을 알 수 있습니다. L2데이터의 경우 OLI 센서를 이용한 밴드 번호(1~7, 9), (8은 panchromatic 밴드라 제외)에 SR이 붙어 있고, TIR센서를 이용한 밴드(10, 11)은 목록에 있지 않습니다. 추가적으로 cfmask, cfmaks_conf, cloud 등의 이름이 추가된 밴드가 있음도 확인할 수 있습니다. SR은 Surface Reflectance의 약어라는 것은 쉽게 눈치를 채셨을텐데요, 그럼 나머지는 무슨 의미일까요? 상단의 .xml 파일을 열어보면 다음과 같은 내용을 확인하실 수 있습니다. cfmask라는 밴드에 대한 설명을 살펴보면 총 5개의 class를 가지고 있음을 알 수 있습니다. 이 중, 0번 클래스는 (구름이나 물 등이 아닌)clear한 영역을, 1~4번 클래스는 순서대로 물, 구름에 의한 그림자, 눈, 구름을 의미합니다. 동일한 방식으로 cfmask_conf 밴드는 4개의 클래스를 가지고 있으며 각 클래스는 구름일 가능성에 대한 신뢰도를 나타냅니다. 즉, 0은 구름일 가능성이 none, 1은 0~12.5%, 2는 12.5~22.5%, 3은 22.5% 초과라는 의미입니다. 언급된 2개의 밴드 중 cfmask를 ENVI에서 열어보면 아래와 같은 이미지를 확인할 수 있습니다.
cfmask라는 밴드에 대한 설명을 살펴보면 총 5개의 class를 가지고 있음을 알 수 있습니다. 이 중, 0번 클래스는 (구름이나 물 등이 아닌)clear한 영역을, 1~4번 클래스는 순서대로 물, 구름에 의한 그림자, 눈, 구름을 의미합니다. 동일한 방식으로 cfmask_conf 밴드는 4개의 클래스를 가지고 있으며 각 클래스는 구름일 가능성에 대한 신뢰도를 나타냅니다. 즉, 0은 구름일 가능성이 none, 1은 0~12.5%, 2는 12.5~22.5%, 3은 22.5% 초과라는 의미입니다. 언급된 2개의 밴드 중 cfmask를 ENVI에서 열어보면 아래와 같은 이미지를 확인할 수 있습니다.
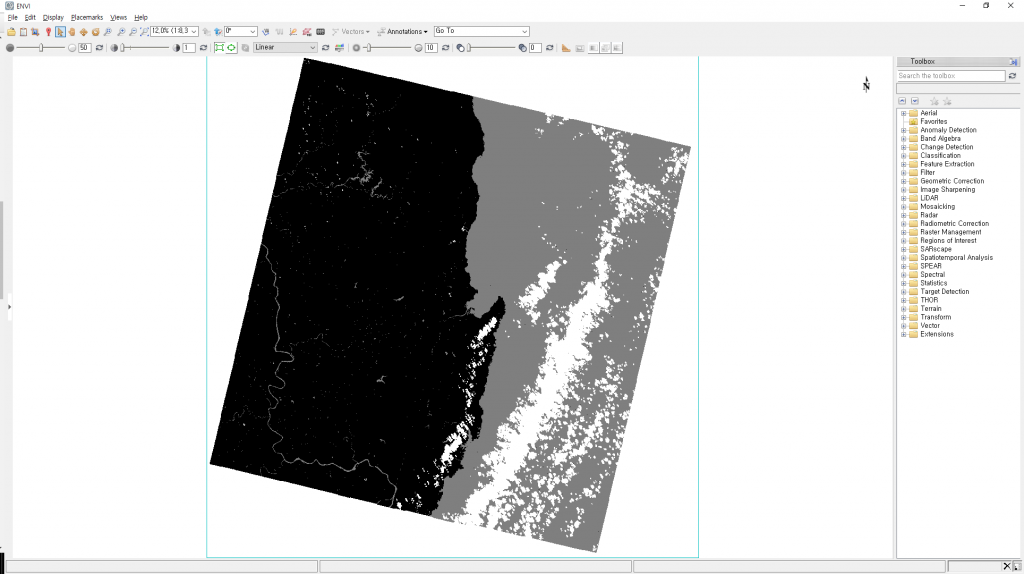
파일 이름과 영상을 통해 눈치를 채셨겠지만, path 및 row가 114/035인 호미곶을 포함하는 우리나라 남동부 지역입니다. 영상에서 왼쪽의 검은색 부분은 대부분 0번 클래스로 구분되어 있고, 영상의 오른쪽과 0번 클래스 내부의 일부는 짙은 회색의 1번 클래스로 구분되어 있습니다. 이는 각각 clear한 영역과 물에 해당하는 영역입니다. 0번 클래스 내 짙은 회색으로 연결된 라인은 낙동강, 오른쪽의 짙은 회색은 동해라는 것을 알아차릴 수 있습니다. 또한 호미곶에서 남쪽 방향으로, 그리고 동해에서도 남북방향으로 길게 늘어선 흰색의 띠는 4번 클래스 즉, 구름이 됩니다. 짙은 회색의 1번 보다 밝은 회색의 2, 3번 클래스- 구름의 그림자와 눈(snow)은 눈(eye)에 잘 띄지 않습니다. 아래의 RGB 합성 영상을 통해 이에 대한 확인을 하실 수 있습니다.
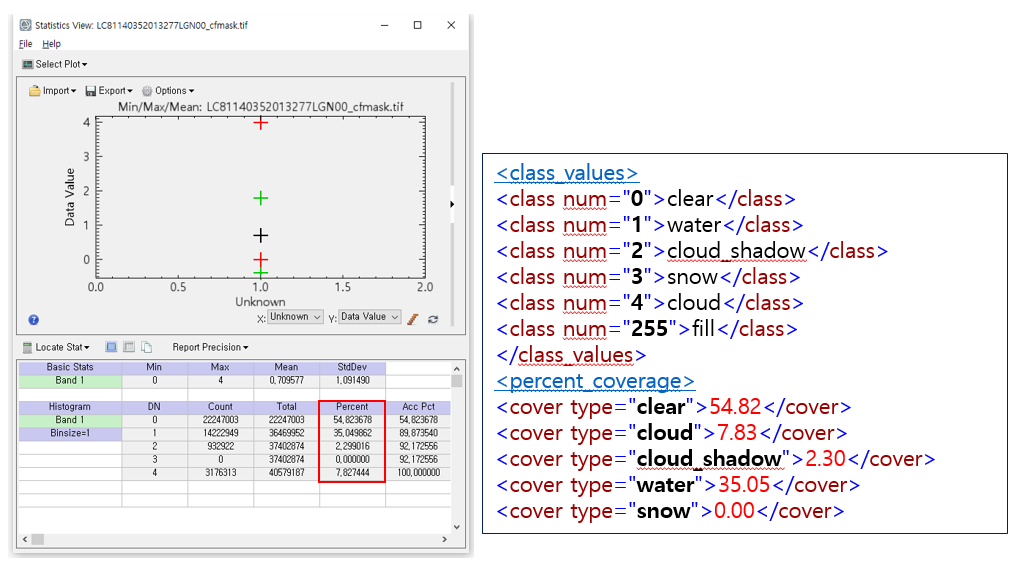
class num 하부를 보니 percent _coverage라는 내용도 보입니다. 이에 대한 내용을 확인하기 위해 ENVI의 view statistics를 실행해보니 아래와 같은 결과가 나오는데요, 소수점 이하 유효자리는 다르지만 동일한 내용임을 알 수 있습니다.
물론 모든 114/035 영상에서 이러한 비율이 동일하게 유지되지는 않습니다. 구름의 영향으로 지표나 물에 해당하는 영역이 가려질 수 있고, 겨울 영상이라면 눈이 추가될 수도 있습니다. 물론 clear한 대기 상태에서도 완벽히 동일한 구분이 되지는 않을 것입니다. 이에 대해서는 사용 전에 충분히 검토를 해야겠지요.
만약 신뢰할 수 있는 클래스 영상을 얻었다면, 해당 영상은 이미지 masking이나 이미지 subset 등에 유용하게 사용될 수 있습니다. 예를 들어 특정 영상에서 물과 관련된 영역에 대해서만, 혹은 눈이 내린 지역에 대해서만 어떠한 연산이나 처리가 필요할 경우 영상 전체를 처리하는 것보다 관심지역에 대한 subset을 수행하여 처리하는 것이 좋습니다. 왜냐하면 데이터 용량이 크게 줄어들기 때문에 시간이나 메모리 측면에서 많은 이득을 볼 수 있기 때문입니다. 이러한 masking과 subset에 대한 내용을 작성하려고 보니 내용이 너무 길어질 것 같습니다. 이에 대해서는 2편 – <Landsat의 Surface Reflectance 데이터의 활용>으로 정리하여 안내해드리도록 하겠습니다. 너무 늦지 않게 정리하여 올리도록 하겠습니다.